



Démystifier le PDF
On connaît tous le PDF, ce format de fichier universel qui permet de préserver à l’identique la mise en page d’un document source.
Le PDF nous facilite bien la vie. En enregistrant un fichier au format PDF, on est assurés que ce qui va sortir de l’imprimante sera la copie conforme de ce qu’on voit sur notre écran d’ordinateur. Enfin ça, c’est la théorie. En réalité, les choses sont un petit peu plus complexes : même le PDF a des failles !
Suivez le guide pour un petit tour d’horizon des principales idées reçues sur le Portable Document Format d’Adobe Systems, plus connu sous le nom de PDF.
Idée reçue #1 : Le PDF conserve la mise en page
L’avantage clé du PDF est sa capacité à conserver la mise en forme d’un document (polices de caractère, images, objets graphiques…) quel que soit l’ordinateur, le système d’exploitation ou l’application utilisés pour le visualiser ou l’imprimer.
Mais il y a des trous dans la raquette ! Le plus gros de ces trous étant, sans aucun doute, la portabilité des polices de caractères : le PDF n’intègre que 14 polices standards alors qu’il en existe des dizaines de milliers, peut-être même des centaines de milliers. Sans compter que de nouvelles polices de caractères sont créées quotidiennement et disponibles dans la foulée au téléchargement sur Internet. 14 polices, c’est peu : Calibri, la police par défaut de Microsoft Word n’est même pas incluse dans le lot !
Que se passe-t-il si le document utilise une police exotique inconnue de PDF ? Deux possibilités :
– Coup de pot, cette police est incorporée dans l’imprimante, le document imprimé est fidèle à l’original. Joie, bonheur, trompettes !
– Manque de chance, l’imprimante ne possède pas non plus cette police. PDF lui substitue alors automatiquement une autre police, en général Courier, ce qui va totalement transformer le document original et atomiser votre mise en page. Attention aux yeux !
Y a-t-il moyen d’utiliser les polices que l’on veut et d’éviter le carnage typographique ? Absolument ! Il suffit dans le PDF que l’on crée de choisir l’option « Incorporer les polices ». Et voilà, le tour est joué.
Idée reçue #2 : Le PDF est un fichier sécurisé
De nombreuses personnes s’imaginent qu’une fois généré, un fichier PDF n’est plus modifiable ou transformable. Mais c’est parfaitement faux !
Il est en fait très facile de faire des modifications dans un PDF, il suffit de quelques clics pour y parvenir lorsqu’on utilise des logiciels tels qu’Acrobat DC.
Mais, me direz-vous peut-être, je peux verrouiller mon PDF avec un mot de passe : mon fichier est alors protégé, non ? Rien n’est moins sûr, car il suffit de quelques secondes pour cracker ces mots de passe sur Internet. En vérité, toute personne déterminée à pirater ou falsifier un PDF trouvera aisément le moyen de le faire. Cette protection par mot de passe ne sert véritablement qu’à une chose : éviter que des personnes bien intentionnées à qui on transmet le document fassent des modifications sans le faire exprès.
Idée reçue #3 : Le PDF est un format universel
Il existe en réalité plusieurs types de PDF, destinés à des usages différents. Outre le PDF classique, on retrouve :
– Le PDF/A, essentiellement utilisé pour l’archivage de documents. Un document papier scanné en PDF/A ne sera pas conservé comme une simple image : grâce à un traitement de reconnaissance de caractères, il sera désormais possible de faire une recherche de mots clés dans le document.
Imaginez par exemple un acte notarié de 200 pages dans lequel vous cherchez une date particulière. Si cet acte est digitalisé en PDF/A, pas besoin d’éplucher le document à la loupe, un simple CTRL+F suffit !
– Le PDF/X, dédié aux professionnels de l’impression. Ce format garantit que le fichier respecte toutes les règles pour une impression parfaite : images d’une résolution adéquate, polices de caractères incorporées, bons profils colorimétriques… Idéal pour les imprimeurs, le PDF/X demeure malheureusement méconnu.
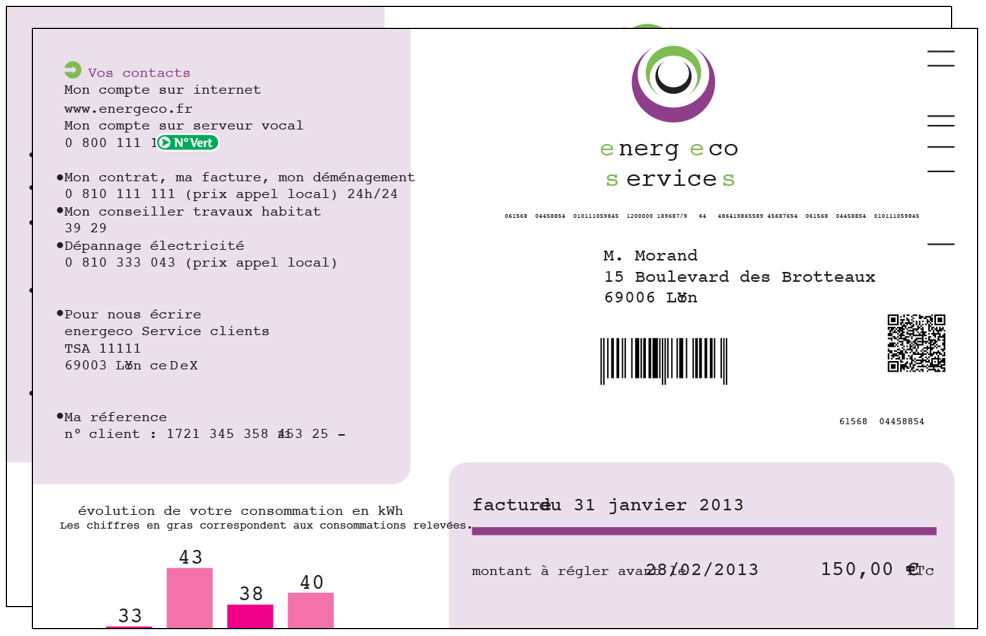
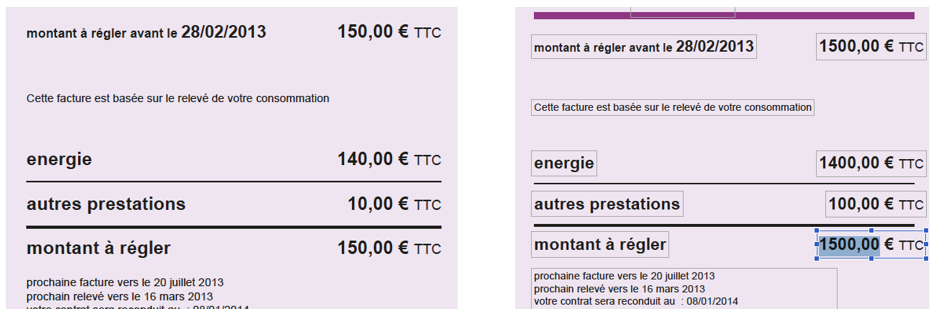
– Le PDF/VT, particulièrement pertinent pour de la facturation. C’est un PDF qui intègre ce qu’on appelle des « variables transactionnelles ». De quoi s’agit-il ? Prenez n’importe quel opérateur téléphonique : il doit émettre pour chacun de ses abonnés une facture similaire intégrant le nom et l’adresse, le montant du forfait et des communications… Plutôt que de produire des centaines de milliers de PDF indépendants sur le même format, l’opérateur produit un PDF/VT beaucoup moins lourd qui n’est autre qu’un masque (le « gabarit » de la facture) auquel viennent s’ajouter les données variables de tous les clients. L’imprimante – il faut bien entendu qu’elle soit capable de gérer ce format – va ensuite intégrer ces données dans le masque et refaire la mise en page.
Idée reçue #4 : Un PDF destiné au web et à l’impression, c’est pareil
Lorsqu’on crée un fichier PDF, on définit un profil complet qui intègre de nombreux paramètres: profil colorimétrique, polices, spécifications des images (couleurs, niveaux de gris, noir et blanc, degré éventuel de compression, rééchantillonnage)…
La résolution standard d’une image en imprimerie est de 300 dpi. Imaginons que nous souhaitions imprimer un document contenant des photos haute définition en 1500 dpi. On peut choisir de conserver cette résolution, mais notre PDF sera très lourd. On peut aussi décider d’indiquer au PDF de rééchantillonner toutes ces photos en 300 dpi : on créera ainsi un fichier plus léger qui reste parfaitement adapté à l’impression.
Et si ce PDF est destiné au web, on peut encore réduire la résolution des images (le standard web est à 72 dpi) pour obtenir un fichier moins lourd, et donc plus rapide à charger, idéal pour un être affichage sur écran d’ordinateur. Mais ce document ne sera plus adapté à une impression papier. Vous avez bien entendu compris le problème : si vous essayez d’imprimer un PDF conçu pour le web, la qualité des images ne sera pas au rendez-vous. 72 dpi, c’est beaucoup trop peu pour une impression de qualité !
En somme, le PDF est moins universel et standard que l’on croit. Et produire un fichier PDF n’est pas nécessairement un gage de qualité et une garantie de succès… Le PDF est un excellent outil, capable de grandes choses, mais il faut apprendre à le maîtriser !

Trois questions à Franz Castel – Responsable Support et Développement Solutions de RISO FRANCE
Pourquoi est-il important de comprendre les spécificités du PDF ?
Tout simplement parce que cela permet dans l’écrasante majorité des cas de comprendre pourquoi un fichier PDF ne s’imprime pas comme il le devrait. 98 fois sur 100, le problème est dans le fichier lui-même !
Bien souvent, le cafouillage vient des polices de caractères. S’il suffit de cocher l’option « Incorporer les polices » pour éviter les désagréments, pourquoi est-ce que ce n’est pas tout simplement proposé par défaut dans PDF ?
Les raisons sont historiques. Au début de la publication assistée par ordinateur (PAO), bien avant Internet, les imprimeurs n’utilisaient qu’un nombre de police restreint. Depuis, si on n’a pas incorporé les polices, c’était pour éviter d’encombrer les disques durs et les réseaux avec des fichiers lourds : cela permettait donc de gagner du temps. Aujourd’hui de nombreux développeurs militent pour que les polices soient incorporées automatiquement dans le fichier PDF.
Comment garantir que le document que je vois à l’écran sera imprimé tel quel ?
Le meilleur moyen de s’en assurer, c’est de faire un contrôle en amont à l’aide d’un logiciel dédié tel qu’Enfocus PitStop. Ce module d’extension pour Adobe Acrobat Pro permet d’analyser tout le fichier PDF pour voir s’il est conforme à l’impression : est-ce qu’il manque certaines polices ? les images sont-elles dans la bonne résolution ?… PitStop va générer un rapport et même permettre de corriger manuellement certaines erreurs constatées. Les logiciels comme PitStop peuvent vraiment apporter une aide précieuse : malheureusement, ces outils restent trop méconnus.









